
Spark is not only a powerful regarding data processing in batch but also in streaming. From version 2.x, Spark provides a new stream processing paradism called structure streaming based on Spark SQL library. This helps developer work with stream process easier compared to DStream API in earlier version. This post will walk through the basic understanding to get started with Spark Structure Streaming, and cover the setting to work with the most common streaming technology, Kafka.
Programming model
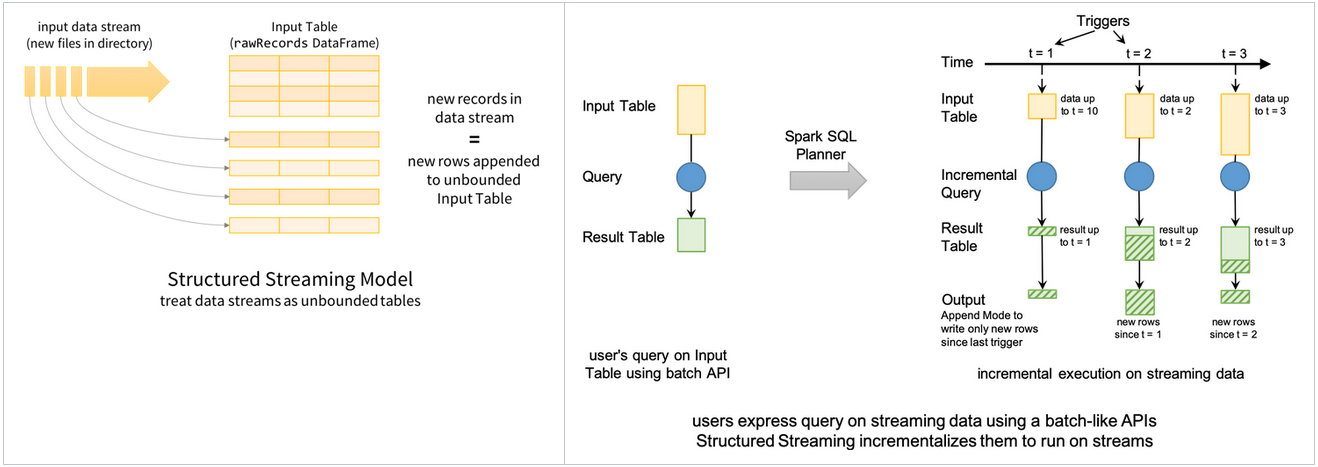
- Consider the input data stream as the “Input Table”. Every data item that is arriving on the stream is like a new row being appended to the Input Table.
- The developer then defines a query on this source, or input table, as if it were a static table to compute a final result table that will be written to an output sink.
- Spark automatically converts this batch-like query to a streaming execution plan. This is called incrementalization: Spark figures out what state needs to be maintained to update the result each time a record arrives.
- Finally, developers specify triggers to control when to update the results. Each time a trigger fires, Spark checks for new data (new row in the input table), and incrementally updates the result.
Anatomy of structured streaming
Explore the a structure of a Spark streaming application by code
1 | (spark.readStream |
Source
- Specify one or more location to read data from
- Built in support for Files/Socket/Kafka/pluggable
Transformation
- Using Dataframe, Datasets and/or SQL. Support both stateless (select, filter, map, etc.) & stateful (group, join, aggregate, etc.) transformations.
- Internal process always exactly-one (Data Delivery Guarantee - each record will be delivered once, no lost or duplicate)
Sink
- Accept the output of each batch
- Support sinks are transactional and exactly one (Files)
Trigger
- Specified as a time, eventually supports data size
- No trigger means as fast as possible
- Trigger modes:
ProcessingTime: This is the default triggering mode which processes streaming data in micro-batches.Once: the streaming query will execute exactly one micro-batch - it processes all the new data available in a single batch and then stops itself. This is useful when you want to control the triggering and processing from an external scheduler that will restart the query using any custom schedule.Continuous: the streaming query will process data continuously instead of micro-batches (experimental in Spark 3.0).Checkpoint location: This is a directory in any HDFS-compatible file system where a streaming query saves its progress information, that is, what data has been successfully processed. Upon failure, this metadata is used to restart the failed query exactly where it left off. Therefore, setting this option is necessary for failure recovery with exactly-once guarantees.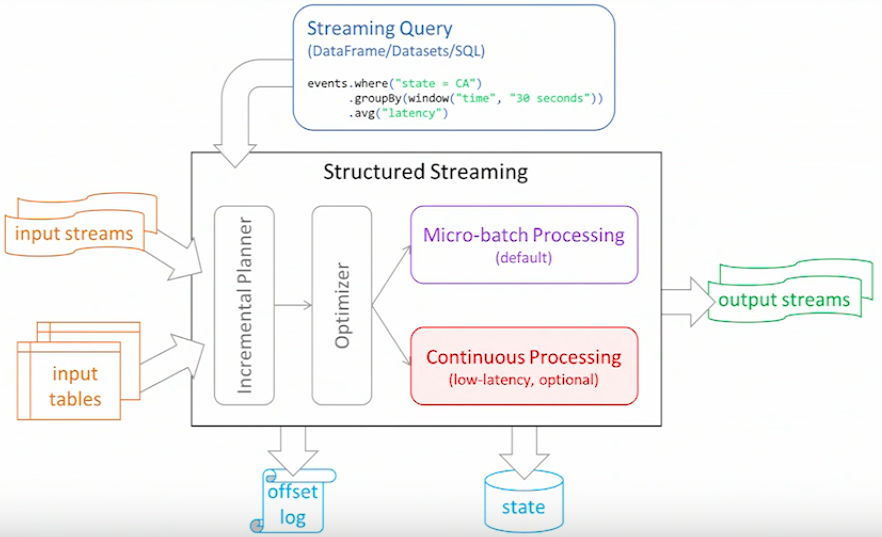
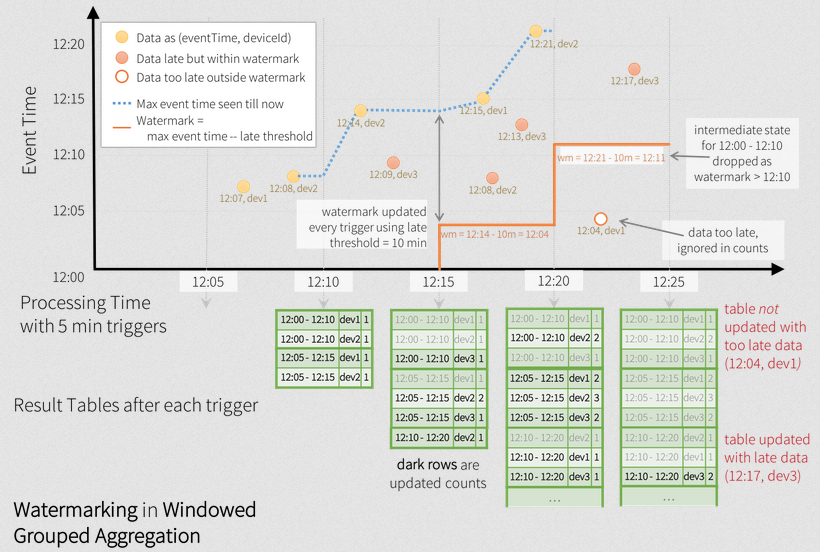
Checkpoint and Watermark
- Track the progress of a query in persistent storage
- Can be used to restart the query if there is a failure
- Watermark to drop late events
Stream ETL example
- Json data being received in kafka
- Parse nested json and flatten it
- Store in structured Parquet table
- Get end to end failure guarantee
1 | raw_data = spark.readStream |
Work with Kafka
Kafka is a popular publish-subscribe system that is widely used for storage of data streams. Structured Streaming has built-in support for reading and writing from Kafka.
Read from Kafka
To perform distributed reads from Kafka, you have to use options to specify information on how to connect to Kafka. Say, you want to subscribe to data from a topic “events”. Here is how you can create a streaming DataFrame.
1
2
3
4
5
6
7input_df = (spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers",
"host1:port1,host2:port2")
.option("subscribe", "events")
.load())The returned DataFrame will have the following schema.
Column Name Column Type Description key binary Key data of the record as bytes. value binary Value data of the record as bytes. topic string Kafka topic the record was in. This is useful when subscribed to multiple topics. partition int Kafka topic’s partition the record was in. offset long Offset value of the record. timestamp long Timestamp associated with the record. timestampType int Enumeration for the type of the timestamp associated with the record. See Kafka documentation. Spark API supports to
- subscribe to multiple topics, a pattern of topics or even a specific partition of a topic.
- read only new data in the subscribed topic, or process all the available data in that topic.
- read Kafka data from batch queries, that is, treat Kafka topics like tables.
Write to Kafka
For writing to Kafka, Structured Streaming expects the result DataFrame to have a few columns of specific names and types.
Column Name Column Type Description key (optional) string or binary If present, the bytes will be written as the Kafka key, otherwise the key will be empty. value (required) string or binary topic (required only if topic not specified as option) string If “topic” is not specified as an option, this determines the topic to write the key-value to. This is useful for fanning out the writes to multiple topics. If “topic” option has been specified, this value is ignored. It can write to Kafka in all three modes, though Complete mode is not recommended as it will repeatedly output the same records. Here is a concrete example of writing the output of our earlier word count query into Kafka in update mode.
1
2
3
4
5
6
7
8
9
10
11
12counts = … # DataFrame[word: string, count: long]
streaming_query = (
counts.selectExpr(
"cast(word as string) as key",
"cast(count as string) as value")
.writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "word_counts")
.outputMode("update")
.option("checkpointLocation", checkpoint_dir)
.start())
Window aggregation
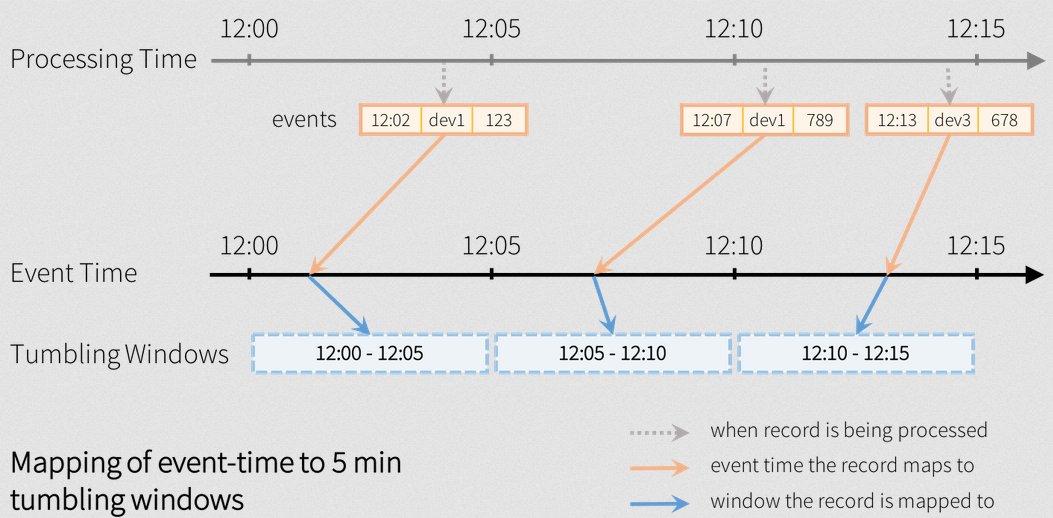
Tumbling window
Example of counting over 5 minute tumbling (non-overlapping) windows on the eventTime column in the event is as following.
1 | from pyspark.sql.functions import * |
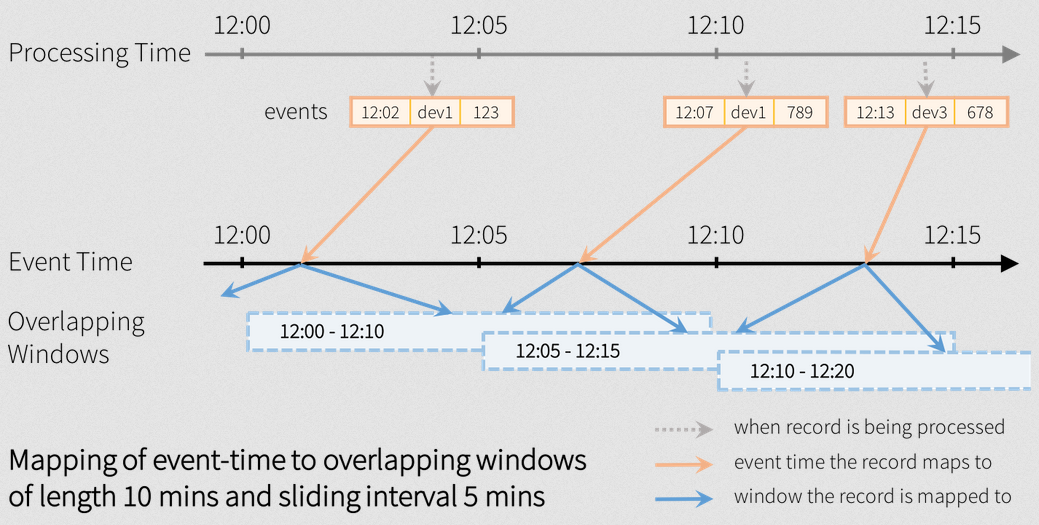
Overlapping windows
Example of counting over overlapping windows on the eventTime of 10 minutes with sliding interval 5 minutes.
1 | from pyspark.sql.functions import * |
Wartermarking
Spark SQL will automatically keep track of the maximum observed value of the eventTime column, update the watermark and clear old state. This is illustrated below.
1 | windowedCountsDF = \ |
Comments