
Spark is an unified engine designed for large scale distributed data processing and machine learning on compute clusters, whether running on-premise or cloud. It replaces Hadoop MapReduce with its in-memory storage for intermediate computations, making it much faster (100x) than Hadoop MapReduce.
Design philosophy
- Speed: firstly, it takes advantage of hardware industry’s huge strides in both CPUs and Memory price and performance. Secondly, it builds query computation as DAG (Directed Acyclic Graph); its DAG scheduler and Catalyst query optimizer construct an efficient computational graph that can be executed in usually in parallel stages, decomposing them as tasks and executing them in parallel across workers on the cluster. Thirdly, its whole-stage code generation physical execution engine, Tungsten, generates compact code for execution.
- Ease of use: Spark provides abstraction of a simple logical data structure called Resilient Distributed Data (RDD) upon which all other high-level structured data abstractions, called Data Frame and Dataset.
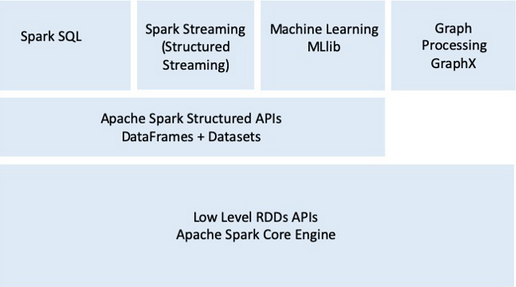
- Modularity: Spark operations are constructed as API can be expressed in multiple programming languages: Scala, Python, Java, SQL and R. It also offers unified library with well-documented API including Spark SQL, Structured Streaming, Machine Learning (MLlib), and GraphX, combining all the workloads running under one engine.
- Extensibility: Spark focuses more on its fast, parallel, computation engine other than on storage. As such, it offers flexibility to read data stored in Hadoop, Cassandra, Hbase, MongoDB, Hive, RDBMS, etc.
Use cases
- Process in parallel large data sets distributed across a cluster
- Perform ad hoc or interactive queries to explore and visualize data sets
- Build, train, and evaluate machine learning models using MLlib
- Implement end-to-end data pipelines from myriad streams of data
- Analyze graph data sets and social networks
Components & concepts
Spark components
- Spark offers four distinct components as libraries for diverse workloads: Spark SQL, Spark MLlib, Spark Structured Streaming, and GraphX. Each component offers simple and composable APIs.
- The component is separate from Spark’s core fault-tolerant engine, in that your Spark code written with these library APIs is translated into a DAG that is executed by the engine. So whether you write your Spark code using the provided Structured APIs in Java, R, Scala, SQL, or Python, the underlying code is decomposed into highly-compact byte code that is executed in the workers’ JVM across the cluster.
Spark SQL
- This module works well with structured data meaning data stored in RDBMS table or read from file with structured data from CSV, Text, Json, Avro, ORC or Parquet.
- There are 2 ways of using Spark SQL: first, using Spark’s Structured APIs in Java, Python, Scala or R; or second, combine SQL-like queries to query data from Spark DataFrame or DataSet.
- Example of using SQL-like in scala as below:
1
2
3
4
5
6
7// read data off Amazon S3 bucket into a Spark DataFrame
spark.read.json("s3://apache_spark/data/committers.json").createOrReplaceTempView("committers")
// issue an SQL query and return the result as a Spark DataFrame
val results = spark.sql("""SELECT name, org, module, release, num_commits
FROM committers WHERE module = 'mllib' AND num_commits > 10
ORDER BY num_commits DESC""")
Spark MLlib
- MLlib contains common classical machine learning (ML) algorithms including classification, regression, clustering, collaborative filtering, build atop high-level DataFrame-based APIs to build predictive models.
- These APIs support to do featurization, to extract or transform features, to build pipelines, and to persist model during deployment.
- Example of using logistic regresstion in python as below:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15from pyspark.ml.classification import LogisticRegression
...
training = spark.read.csv("s3://...")
test = spark.read.csv("s3://...")
# Load training data
lr = LogisticRegression(maxIter=10, regParam=0.3, elasticNetParam=0.8)
# Fit the model
lrModel = lr.fit(training)
# predict
lrModel.transform(test)
...
Spark Structure Streaming
- Structured Streaming APIs is built on top of the Spark SQL engine and DataFrame-based APIs. It treated streaming source as a structured table and issued queries against it as they would a static table.
- Example of reading Kafka stream in python:
1
2
3
4
5
6
7
8
9
10
11
12
13
14# read from Kafka stream
lines = (spark.readStream
.format("kafka")
.option("subscribe", "input")
.load())
# perform transformation
wordCounts = (lines.groupBy("value.cast(‘string’) as key")
.agg(count("*") as "value") )
# write back out to the stream
query = (wordCounts.writeStream()
.format("kafka")
.option("topic", "output"))
GraphX
- GraphX is a library for manipulating graphs (e.g., social networks graphs, routes and connections points, network topology) and performing graph-parallel computations.
- Blow code snippet shows a simple example of how to join two graphs using the GraphX APIs.
1
2
3
4
5val graph = Graph(vertices, edges)
messages = spark.textFile("hdfs://...")
graph2 = graph.joinVertices(messages) {
(id, vertex, msg) => ...
}
Spark Execution
- At a high level in the Spark architecture, a Spark application consists of a driver program that is responsible to orchestrate parallel operations on the Spark cluster.
- The driver accesses all the distributed components: Spark Executor and Cluster Manager in the cluster through a SparkSession.
- To dig dive deeper into the Spark execution, you can find it helpful from Spark hierarchy
Spark Session
- Initiate spark instance to be able to conduct Spark operations
- Example code in scala:
1
2
3
4
5
6
7
8
9
10
11import org.apache.spark.sql.SparkSession
// build SparkSession
val spark = SparkSession().builder()
.appName("LearnSpark")
.config("spark.sql.shuffle.partitions", 6)
.getOrCreate()
...
val people = spark.read.json("...")
...
val resultsDF = spark.sql("SELECT city, pop, state, zip FROM zips_table")
Spark Driver
- Initiate SparkSession
- Communicate with the Cluster Manager
- Request resources from the Cluster Manager for Spark’s Executors JVMs (CPU, Memory, Disk, etc.)
- Transforms Spark operations into DAG computations, schedule them, and distribute their executions as tasks across all Spark Executors
Cluster Manager
- Manage and allocate resources for cluster of nodes which the Spark application running on.
- Spark currently supports built-in standalone, Yarn, Mesos and Kebernetes.
Spark Executor
- Run on each “worker” node in the cluster (often called Spark worker).
- Launch Executor on which Spark’s tasks run
Deployment modes
- There are some terminologies used once work with Spark deployment listed below:
- Job: A piece of code which reads some input from HDFS or local, performs some computation on the data and writes some output data
- Stages: Jobs are divided into stages. Stages are classified as a Map or reduce stages (Its easier to understand if you have worked on Hadoop and want to correlate). Stages are divided based on computational boundaries, all computations (operators) cannot be Updated in a single Stage. It happens over many stages.
- Tasks: Each stage has some tasks, one task per partition. One task is executed on one partition of data on one executor (machine).
- DAG: DAG stands for Directed Acyclic Graph, in the present context its a DAG of operators.
- Executor: The process responsible for executing a task.
- Master: The machine on which the Driver program run
- Slave: The machine on which the Executor program runs
- List of deployment mode for further reference
Mode Spark Driver Spark Executor Cluster Manager Local Runs on a single JVM, like a laptop and a single node. Runs on the same JVM as the driver Runs on the same host. Standalone Can run on any node in the cluster Each node in the cluster will launch its own Executor JVM Can be allocated arbitrarily to any host in the cluster YARN (client) On a client, not part of the cluster YARN’s NodeManager’s Container YARN’s Resource Manager works with YARN’s Application Master to allocate the containers on NodeManagers for Executors YARN (cluster) Runs with the YARN’s Application Master Same as YARN client mode Same as the YARN client mode Mesos (client) Runs on a client, not part of Mesos cluster Container within Mesos Agent Mesos’ Master Mesos (cluster) Runs within one of Mesos’ Master Same as client mode Mesos’ Master Kubernetes Kubernetes pod Each worker runs within its own pod Kubernetes Master
References
- Learning Spark 2nd edition: https://learning.oreilly.com/library/view/learning-spark-2nd/9781492050032/
Comments