
Hadoop can handle with very big file size, but will encounter performance issue with too many files with small size. The reason is explained in detailed from here. In short, every single on a data node needs 150 bytes RAM on name node. The more files count, the more memory required and consequencely impacting to whole Hadoop cluster performance.
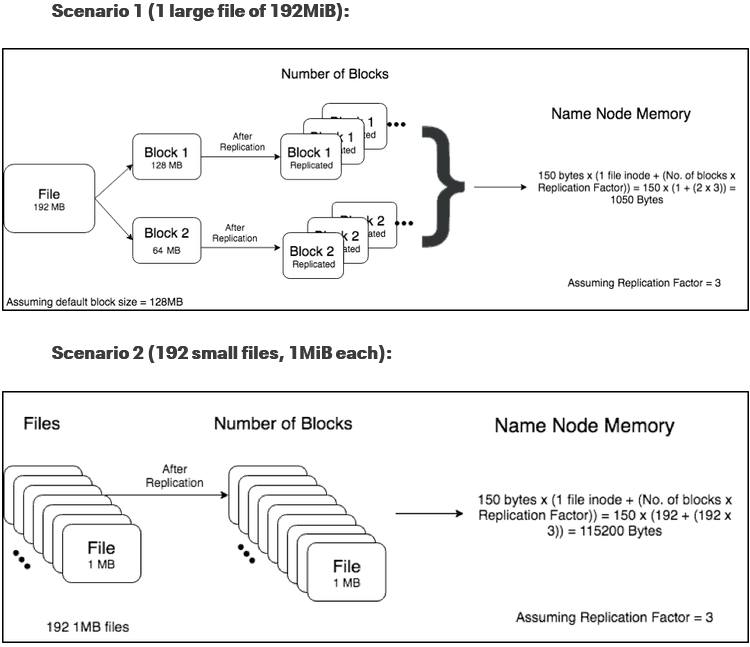
Below picture shows a clear affects of storing too many files on HDFS with default block size of 128 MB and replication factor of 3. In scenario 1, we have 1 file 192MB which is splitted to store in two blocks. Those blocks will be then replicated into 3 different blocks. So total, it only needs 2*3 = 6 blocks.
On the contrary, scenario 2 dealing with the same file but splitted into 192 files, 1MB each. This resulted into 192*3 = 576 blocks. And with the name node memory calculation, scenario 2 takes more than 100x memory needed on name node compared to scenario 1.
In practice, we’ve exprienced the slowness on querying data from Hive, Impala and Spark applications on table stored up to several million files within a single partition. In addition to that, services deployed on name node encounter low performance (Zeppelin, etc.).
How small files orginated & How to prevent?
Streaming job is one of sources generating so many files. It depends on how window time is set, the longer windows time, the less number of files written to HDFS but the trade-off is latency reduced.
Batch job with large number of mappers/reducers on MapReduce, or request so many partitions when storing data to disk on Spark application (Default is 200 partitions). For this case, it can be prevented by proactively configurating number of data files writing down to HDFS.
MapReduce: configure hive setting as below example:
1
2
3
4
5
6
7
8
9
10set hive.exec.compress.output=true;
set hive.exec.parallel = true;
set parquet.compression=snappy;
set hive.merge.mapfiles=true;
set hive.merge.mapredfiles=true;
set hive.merge.smallfiles.avgsize = 134217728; --128M
set hive.merge.size.per.task = 268435456; --256M
set hive.optimize.sort.dynamic.partition = true;
set parquet.blocksize= 268435456; --256M
set dfs.block.size=268435456; --256MSpark: apply
coalesceorrepartitionat step of insert data into a table. How to use these function effectively, it worths spending time of reading this post from AirBnB engineering team.
For existing tables with many small files, to fix this issue will need a tool. I did write a pyspark tool called
spark-kompactorto overcome this problem in our circumstance of many tables under line with so many small files generated by Hive or Spark batch jobs.
What is spark-kompactor
This is a tool written in pyspark to compact small files underline for Hive tables on HDFS. This help to reduce the workload burdon on Name Node of a Hadoop cluster.
How it works
The tool works for only table having partitions and run on scheduled for maintaining purpose. This will help to prevent conflict writting on latest partition as most of our jobs are running in incremental manner. Below steps showing its compacting operation:
- Scan partitions on provided table
- Count number of files and total size for each partition
- Checkout data of each partition, repartition it (compacting) based on default block size.
- Overwrite partition with repartitioned data
To prevent the conflict writing, within spark configuration, the
spark.hadoop.hive.exec.stagingdiris configured to write to other directory instead of default one.
How to run it
As this is a Spark application, simply run below spark-submit command with your input table name. Bear in mind that, your account should be accessible and have DML privilege to that table.
1 | spark-submit --master yarn --deploy-mode client --driver-memory 2g \ |
References
- Small Files, Big Foils: Addressing the Associated Metadata and Application Challenges
- On Spark, Hive, and Small Files: An In-Depth Look at Spark Partitioning Strategies
- Building Partitions For Processing Data Files in Apache Spark
- Compaction / Merge of parquet files
- Why does the repartition() method increase file size on disk?
Comments