Agents become truly useful when they can interact with the real world - fetching live data from APIs, querying databases, and writing results back. This post covers building production-grade integrations: API tools with proper error handling, SQL agents that translate natural language to queries, and security patterns that prevent disasters.
LangGraph - State Graphs for Agentic Workflows
LCEL chains are powerful but limited - they can’t loop, branch dynamically, or maintain complex state between steps. LangGraph solves this by modeling agent workflows as state machines: graphs where nodes are processing steps and edges define control flow. This explicit structure enables cycles, conditional routing, and persistent state that production agents require.
Building Agents with LCEL and Tool Integration
The LangChain Expression Language (LCEL) transforms how we build LLM workflows. Instead of managing execution flow manually, LCEL lets you compose components declaratively - like Unix pipes for AI. Combined with tool integration, LCEL enables building agents that reason and act in the real world.
Mastering LangChain and LangGraph - A Practitioner's Guide
If you’ve been building with LLMs, you’ve likely encountered the gap between simple API calls and production-ready agent systems. LangChain and LangGraph bridge that gap, providing the abstractions and patterns needed to build reliable, maintainable AI applications. This series takes you from LangChain fundamentals to production multi-agent systems, focusing on practical implementation over theory.
Churn rate prediction on Sparkify service

Spakify is a music streaming sevice as similar to Spotify. Every users’ activities on Sparkify application are logged and sent to Kafka cluster. To improve the business, the data team will collect data to a Big Data Platform for further processing, analysing and extracting insights info for respective actions. One of the focusing topic is churn user prediction.
Deserialize Avro Kafka message in pyspark
Recently, I worked on a project to consume Kafka message and ingest into Hive using Spark Structure Streaming. I mainly used python for most of the work with data pipeline construction, and this project is not exception.
Everything moved smoothly at the beginning when launching first Spark Structure Streaming to read simple message in raw text format from Kafka cluster. The problem was rising when I tried to parse the real Kafka message serialized in Avro format.
Vietnam stock data analysis

The goal of this project is to collect and visualize the stock price of all tickers in Vietnam. There is quite limited access to API for a single business user, this project aim at scrap data from website, clean, extract and load into data warehouse. The final product is a maintainable/reliable data pipeline with exposed analytic dashboard hosted on cloud, and end authorized users can access to 24/7 with daily updated data.
Car make & model recognition
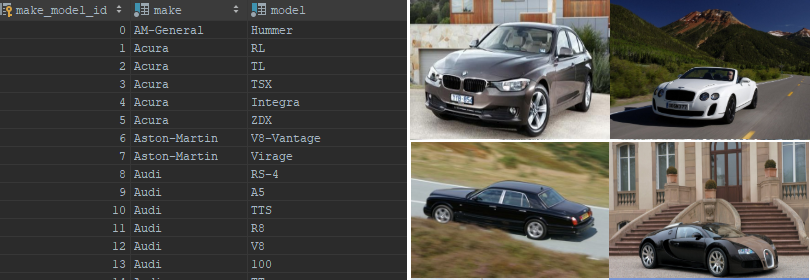
This project aims at recognizing the car make and model based on a Stanford Cars Dataset with 16,185 images. This dataset includes information about car make, model, and year (Eg. 2012 Tesla Model S) with 196 different classes. However, in this project we target to identify the car make and model only; this results in 164 different classes in total.