
Apache Kafka is a distributed streaming platform. It is used for building real-time data pipelines and streaming apps. It is horizontally scalable, fault tolerant, wicked fast, and runs in production in thousands of companies.
This post is my notes once started learning about Kafka. Most resources referred from Apache Kafka Series - Learn Apache Kafka for Beginners - by Stéphane Maarek
Introduction
Kafka possesses three key capabilities:
- Publish and subscribe to streams of records, similar to message queue technologies like RabbitMQ, Google PubSub, AWS SQS, etc.
- Store streams of records in a fault-tolerant durable way.
- Process streams of records as they occur.
Kafka has four core APIs:
- Producer API: allows application to publish stream of records to one or more Kafka topics.
- Consumer API: allows application to subscribe to one or more topics and process the stream of records produced to them.
- Streams API: allows application to act as a stream processor, consuming an input stream from one or more topics and producing an output stream to one or more output topics, effectively transforming the input streams to output streams.
- Connector API: allows building and running reusable producer or consumers that connect Kafka topics to existing applications or data systems.
First few concepts:
- Kafka is run as a cluster on one or more servers that can span multiple data centers.
- The Kafka cluster stores streams of records in categories called topics.
- Each record consists of a key, a value, and a timestamp.

Use cases
- Messaging system
- IoT and sensor network
- Stream processing (with Kafka Stream API or Spark)
- Integration with Spark, Flink, Storm, Hadoop and many other Big Data technologies
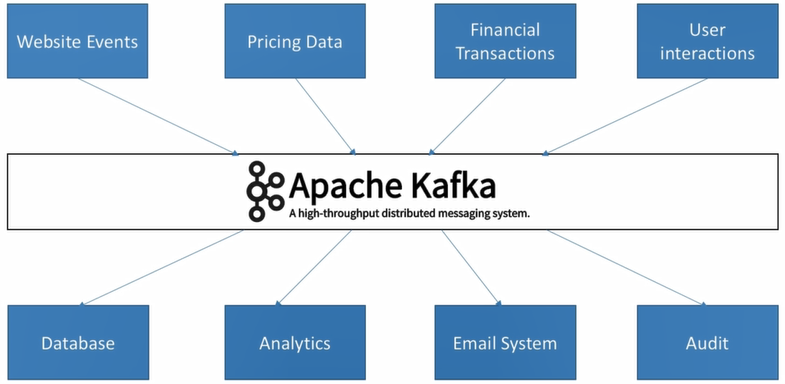
Terminologies summary
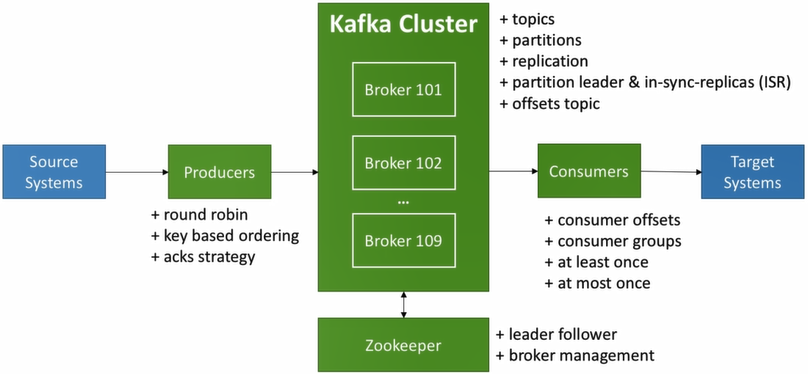
The diagram describes a complete Kafka application from source to target systems with number of terminologies living within Kafka cluster. Below sections will briefly explain their working principles.
Topic, partition, record and offset
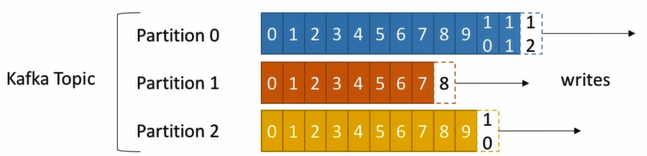
- Topics is a particular stream of data and identified as unique name.
- Partitions are subsets of a particular topic. At step of creating topic, it is able to declare how many partitions associated with it.
- Records are subset of a specific partition and stored in ordered as time arriving that partition. It is a message with a pair of key, value and other meta data like timestamp, compression, offset, key, etc.
- Offset presents position of a record within a partition, it is simply sequential ID number to identify every single record.
Some worth noting in this section:
- Record is only kept for a limited time (default 1 week) or thread-hold storage size (configurable).
- Record is immutable once written to a partition.
- Record is assigned randomly to a partition
unless a key is provided.
Broker
Broker
- A Kafka cluster is composed of multiple brokers (servers)
- Each broker is identified with its ID (integer)
- Each broker contain certain topic partitions
- After connecting to any broker, it is able to connect to the entire cluster
Below image shows three brokers stored two topics with different number of partitions.
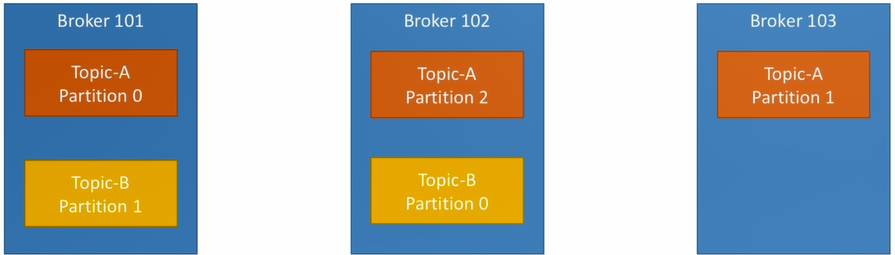
Broker and topic
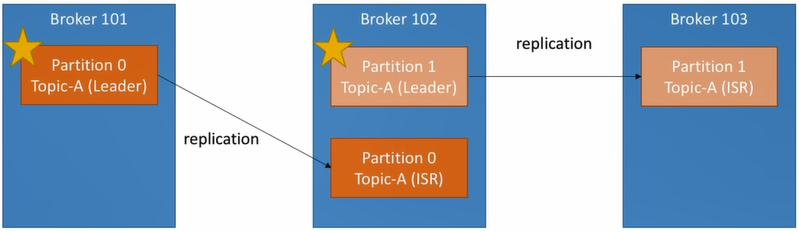
- Once replication is enabled, depending on replicator factor setting, every single partition will be replicated to other broker(s).
- At any time, only one broker can be a leader for a given partition
- Only that leader can receive and serve data for a partition
- Other brokers will synchronize the data
- One typical partition will has one leader and multiple ISR (in-sync replica)
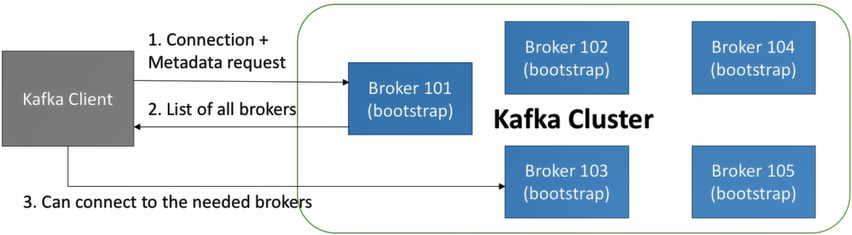
Broker discovery
- Every broker also called a “bootstrap server”
- Every client only need to connect to one broker, it can connect to entire cluster
- Each broker know about all other brokers, topics and partitions (meta data)
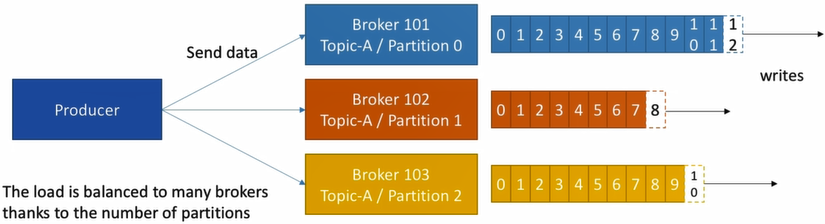
Producer
Producer
- Producers transmit data to topics which is made of partitions
- Producer automatically know to which broker and partition to write to
- In case of broker failures, producer will automatically recover
- Producer can choose to receive acknowledgement of data writes:
- acks=0: not wait for acknowledgement (possible data loss)
- acks=1: wait for leader acknowledgement (limited data loss) ← prefer
- acks=all: wait for leader and replicas acknowledgement (no data loss)
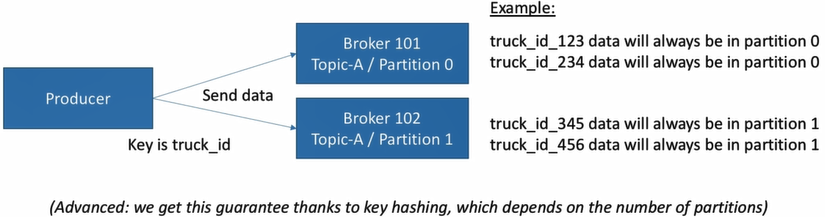
Producer with key
- Producer can choose to send a record with a key (could be string, number, etc.) of specific topic
- By default, key=null then data is send in round robin way (eg. broker 101 → broker 102 → broker 103)
- If key is sent, all records with same key will be stored in same partition
- Use case: ensure records are arrange in order within specific field (partition) as below example.
Consumer
Consumer
- Consumer read data from a topic
- Consumer knows which broker to read from
- In case broker failures, consumer know how to recover
- Data is read in order within each partition
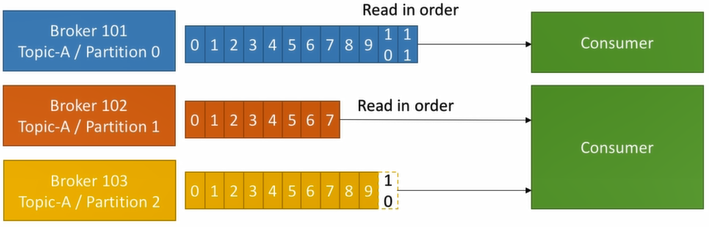
Consumer group
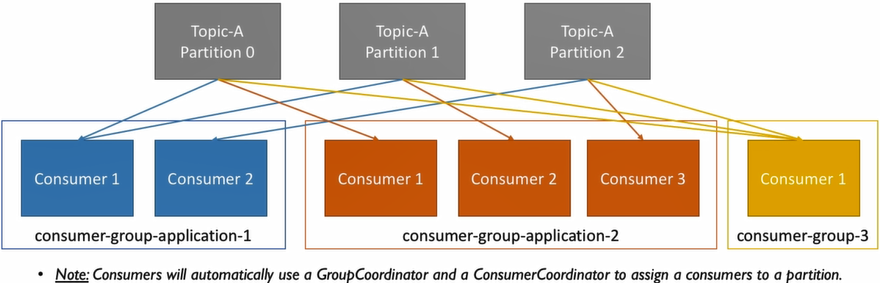
- Consumers read data in consumer groups
- Each consumer within a group reads read from exclusive partitions
- If #consumers within a group > #partitions, some consumers will be inactive
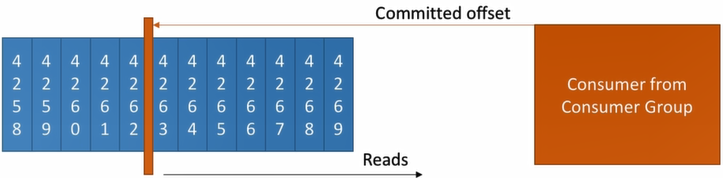
Consumer offset
- Kafka stores the offsets at which a consumer group has been reading
- The offsets committed live in a Kafka topic named __consumer_offsets
- When a consumer in a group has processed data received from Kafka, it should be committing the offsets.
- If a consumer dies, it will be able to read back from where it left off.
Delivery semantics
- Consumer can choose which type of delivery semantic when to commit offsets
- There are 3 delivery semantics:
- At most once:
- Offsets are committed as soon as the message is received
- If processing goes wrong, the message will be lost (it wont be read again)
- At least once:
- Offsets are committed after the message is processed
- If the processing goes wrong, the message will be read again
- This can result in duplicate processing of messages. Make sure your processing is idempotent.
- Exactly once:
- Can be achieved for Kafka to Kafka workflows using Kafka Stream API
- For Kafka to external systems workflows, use an idempotent consumer
- At most once:
Zookeeper
- Zookeeper manages brokers
- Zookeeper helps in performing leader election for partitions
- Zookeeper send notifications to Kafka in case of changes (eg. new topic, broker dies, broker come up, delete topics, etc.)
- Kafka cannot work without Zookeeper
- Zookeeper by design operates with an odd number of servers (3, 5, 7)
- Zookeeper has a leader (handle writes) the rest of the servers are followers (handle reads)
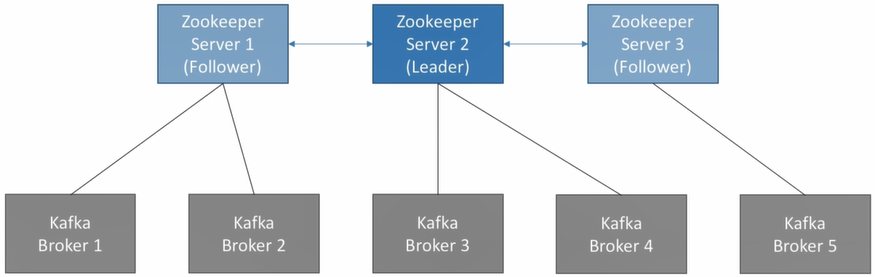
Currently, there is an effort to remove Kafka dependency on Zookeeper to make it a simpler architecture, ease of operations and better scalability.
Comments