In our last post, we explored the topic of the Data Platform on AWS. This post continues the discussion by offering an in-depth look into the central component of the data platform, the data lake, which serves as the single source of truth.
A data lake is a centralized repository for storing structured and unstructured data at any scale. It helps organizations effectively store, manage, and analyze growing amounts of data. Building a data lake on AWS offers cost-effective, secure storage and real-time analysis using scalable infrastructure, robust security, and analytical tools for making data-driven decisions and improving business value.
The proposed architecture is presented as below with 5 main components Ingestion, Storage, Processing, Meta Data & Governance and Orchestration.
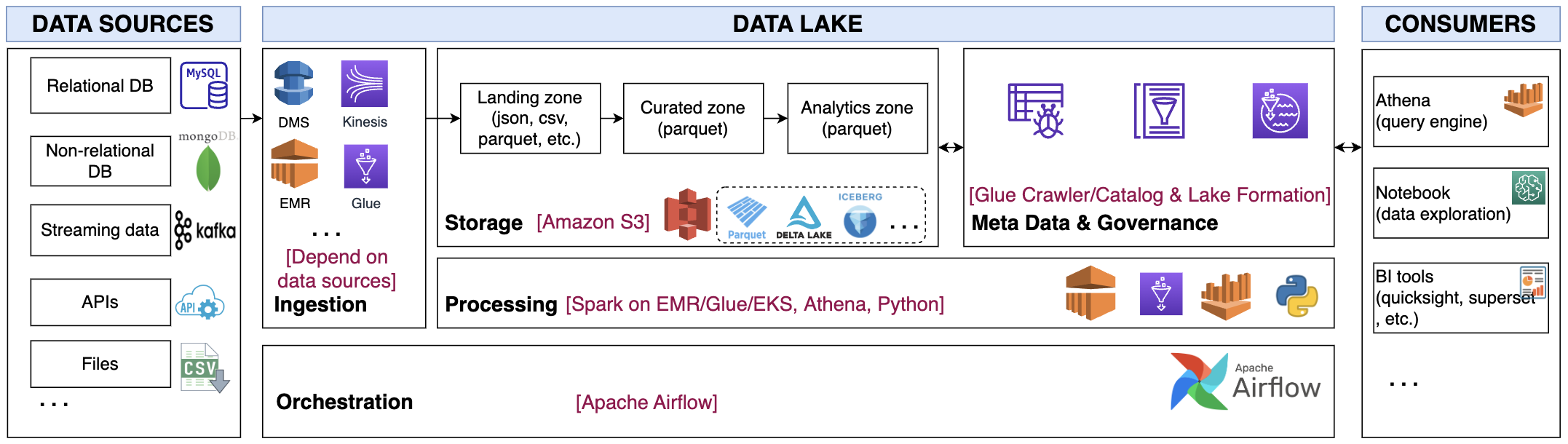
Ingestion
This component involves acquiring data from various sources and storing it in its raw format within the storage layer. The tools used in this stage may vary based on the nature of the data source. Some examples include:
Relational/NoSQL databases: For transactional data, a data management system (DMS) can be employed to capture only changes in records and transfer them to S3 for improved latency. Another option is to use EMR or Glue with either an incremental or full load approach, and then store the data in Parquet format on S3.
Streaming: The Kinesis family of services can simplify the process of consuming streaming data, with native integration to AWS S3. Spark streaming on EMR can also be utilized to capture data streams from Kafka.
APIs: Custom python scripts or available client software development kits can be employed to extract the relevant data and write it to the data lake. Third-party connectors, such as FiveTrans, can also be utilized.
Files: The method used for extracting files may depend on their location. For instance, if the files are located on an SFTP server, they can be extracted using a simple scheduled bash script. If the files are on Google Drive, the Google-python-api module can be utilized.
Storage
Data will be stored on S3 in 3 different zones:
- Landing zone: This is where data is stored in its raw format.
- Curated zone: This is where data is validated and structured by Data Engineers.
- Analytics zone: This is where data is transformed for specific business purposes by Data Analysts and Data Scientists.
Parquet format is chosen for storage in the Curated and Analytics zones due to its optimal compression and fast querying speeds. Delta Lake is employed for its ACID features when handling transactional data. Governed Tables cloud be an option but it is not fully support for now.
Processing
For data extraction, load, and transformation, Spark on EMR/Glue, Athena, or Python is selected based on the specific use case. When dealing with large data processing, Spark on EMR/Glue is the preferred choice. However, Athena or Python is more useful for complex ETL processes or deployment of machine learning models.
Glue offers a fast and efficient way to implement ETL jobs, with automatic Spark code generation and pre-built blueprints. EMR, on the other hand, provides more customization options for Spark clusters and is a cost-effective solution.
Meta Data and Governance
To effectively manage your data lake, metadata and governance are crucial components. Fortunately, Glue Data Catalog and Lake Formation offer pre-built features for organizing data and controlling data access and policy. Users with proper permissions can easily query data using standard SQL commands via Athena. Additionally, the Glue Crawler simplifies the process of generating metadata for S3-stored data with a few simple steps.
Orchestration
Apache Airflow is selected as it provides more flexibility in scheduling from simple to complex data pipeline. With workflow as code in python, it is easier for DE/DS to compose the pipeline quickly. In the next post, we will explore into how Airflow placed into the AWS infrastructure.
Comments