As AI continues to impact the world, the importance of data in business decision making has become increasingly apparent. Data also offers the potential to deliver greater value with less effort. To fully realize these benefits, it is essential to prioritize the development of a robust data platform architecture.
This series begins with the goal of constructing a comprehensive data platform on AWS, designed to meet the diverse needs of companies from startups to enterprises. Our objective is to create a platform that is scalable, reliable, secure, flexible, and cost-effective.
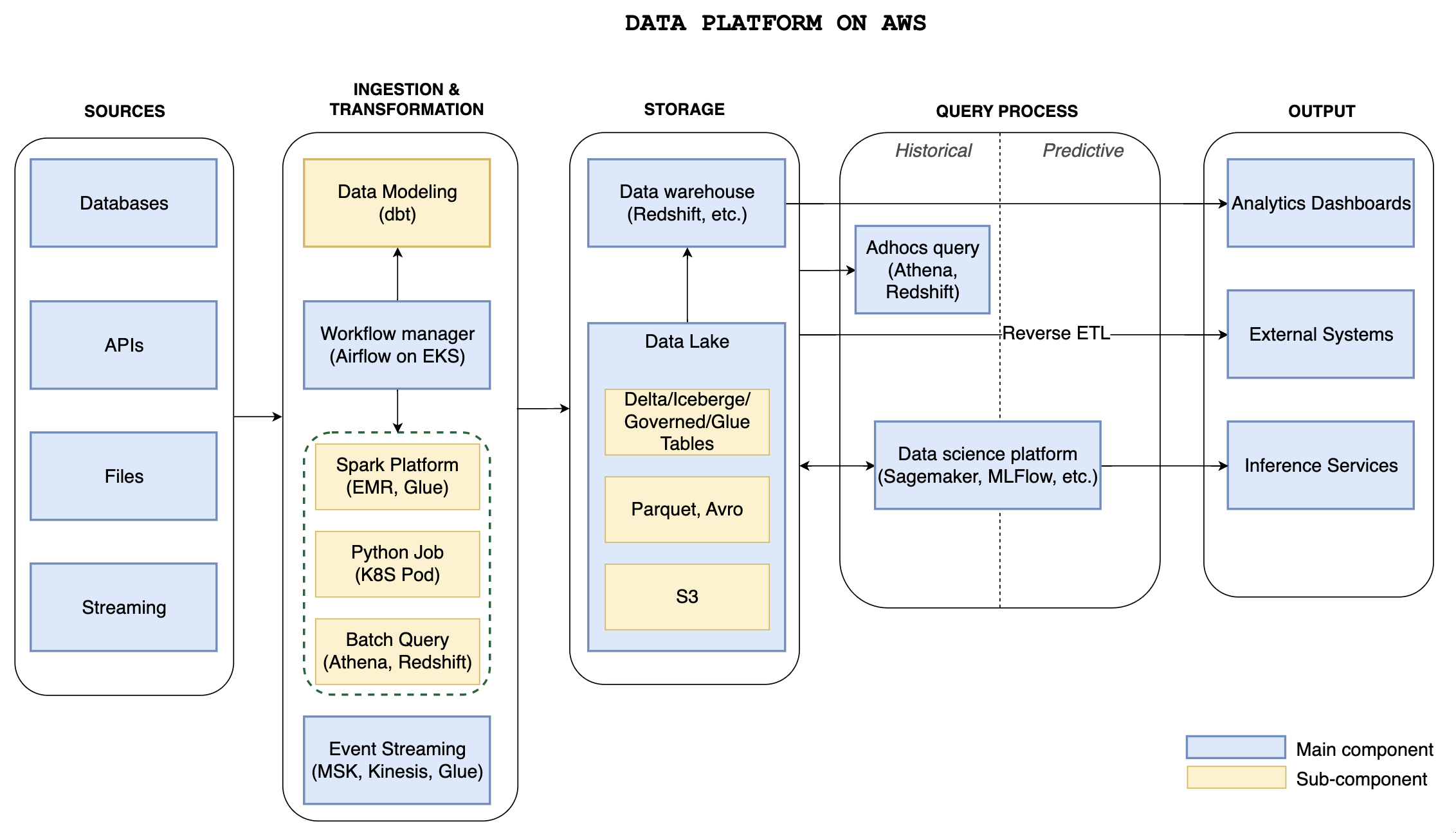
Above diagram shows a comprehensive data platform built on top of AWS infrastructure.
Sources
The Data Platform ingests data from a diverse range of sources, such as databases, APIs, files, and streaming sources, which can be either internal or external to the organization.
Ingestion and Transformation
Data ingestion can be facilitated by both managed services and open-source tools, making it possible to avoid vendor lock-in concerns when selecting the appropriate toolset for the architecture.
For handling big datasets, Spark jobs can be deployed on Amazon EMR or through serverless services such as AWS Glue. Lightweight transformations and smaller data sets can be processed using a Python job.
To perform SQL queries on large datasets, it is often best to offload the workload to AWS Athena or Amazon Redshift. This is especially important for model building within a data warehouse, where dbt shines as a dedicated tool.
All tasks and jobs are organized within workflows and managed by Apache Airflow, and the underlying infrastructure is hosted on Amazon EKS with Kubernetes, which provides scalability for any workload.
Analytics Workflow based on DL & DWH
The analytics workflow is a crucial process in the data-driven decision making process. It consists of three main outputs, each serving a unique purpose in the analysis of data.
Analytics dashboards: provide a visual representation of the data and allow users to interact with the data in real-time, providing insights and identifying trends.- The second output is
the sending of data to an external systems, which can be used to perform further process in other applications. This is often call Reverse ETL. - The third output is
the deployment of inference services, which rely on machine learning models to make predictions based on the data. These models can be used to automate decision making, reducing the time and effort required to analyze data and providing actionable insights.
A Data Lake designed on AWS S3 using the Parquet file format enhances analytics performance. The tool, Lake Formation, facilitates seamless access to the open data format, such as Parquet, using SQL and enables metadata and governance capabilities on AWS. The recent advancements in big data query abstraction, such as Delta Lake, Apache Iceberg, and AWS Governed Table, have made it easier for analytics teams to use and increased their satisfaction. Data Scientists can use various data sources from Data Lake to build predictive models and deliver inference services with defined inputs.
A part from Data Lake, Data Warehouse plays a vital role where it enables the ability to extract meaningful insights from their data and drive business metrics. Data Analysts can utilize this component to build insightful dashboards.
In the next post, we will devle into Data Lake design.
Comments