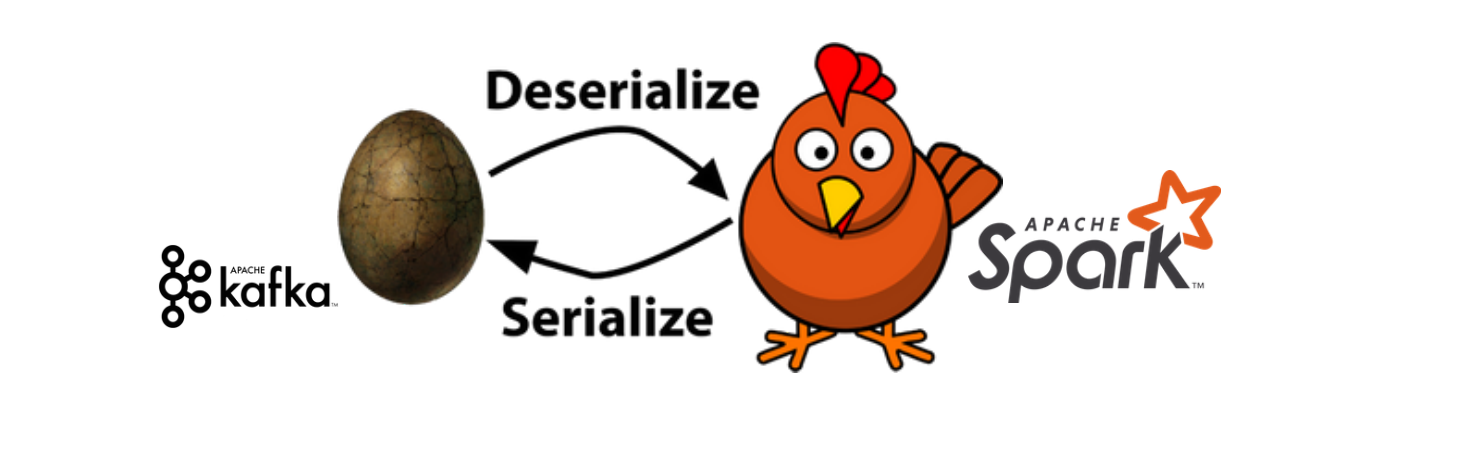
Recently, I worked on a project to consume Kafka message and ingest into Hive using Spark Structure Streaming. I mainly used python for most of the work with data pipeline construction, and this project is not exception.
Everything moved smoothly at the beginning when launching first Spark Structure Streaming to read simple message in raw text format from Kafka cluster. The problem was rising when I tried to parse the real Kafka message serialized in Avro format.



