Middleware and concurrency are two powerful features that make Go excellent for backend development. Middleware enables cross-cutting concerns like logging and authentication, while Go’s goroutines and channels provide elegant solutions for concurrent processing. This post explores both patterns in depth.
Building REST APIs with Go and Gin
Gin is Go’s most popular web framework, offering a martini-like API with up to 40x better performance. This post covers building production-ready REST APIs with Gin, from basic routing to data validation and CRUD operations.
Database Migrations in Go
Database migrations are essential for managing schema changes in production applications. As your application evolves, your database schema must evolve with it - adding tables, modifying columns, creating indexes. This post covers migration strategies and tools for Go applications, with a focus on safe, reversible changes.
Mastering GORM: Go's Powerful ORM
GORM is Go’s most popular Object-Relational Mapping (ORM) library, providing an elegant way to work with databases using Go structs. Instead of writing raw SQL, GORM lets you interact with database records as Go objects, handling the translation between your code and the database automatically.
PostgreSQL Fundamentals for Go Developers
PostgreSQL is one of the most powerful open-source relational databases, and it pairs exceptionally well with Go for backend development. This post covers PostgreSQL fundamentals and demonstrates how to connect and interact with Postgres from Go using the pgx driver - the most performant PostgreSQL driver for Go.
Why Go for Backend Development
Go (or Golang) has emerged as one of the most compelling choices for backend development. Originally created at Google to address challenges in building large-scale, concurrent systems, Go combines the efficiency of compiled languages with the simplicity of modern programming practices. This post explores why Go is an excellent choice for backend development and when you should consider using it.
Airflow on EKS

Airflow is a powerful platform to automate and manage workflows. There are several options to deploy Airflow on AWS, including MWAA, ECS OR EKS:
- Deploying Airflow on AWS Managed Workflow for Apache Airflow (MWAA): This option provides a fully managed service for Apache Airflow and is a good choice for those who want a quick and easy way to get started with Airflow on AWS.
Data Lake on AWS
In our last post, we explored the topic of the Data Platform on AWS. This post continues the discussion by offering an in-depth look into the central component of the data platform, the data lake, which serves as the single source of truth.
A data lake is a centralized repository for storing structured and unstructured data at any scale. It helps organizations effectively store, manage, and analyze growing amounts of data. Building a data lake on AWS offers cost-effective, secure storage and real-time analysis using scalable infrastructure, robust security, and analytical tools for making data-driven decisions and improving business value.
The proposed architecture is presented as below with 5 main components Ingestion, Storage, Processing, Meta Data & Governance and Orchestration.
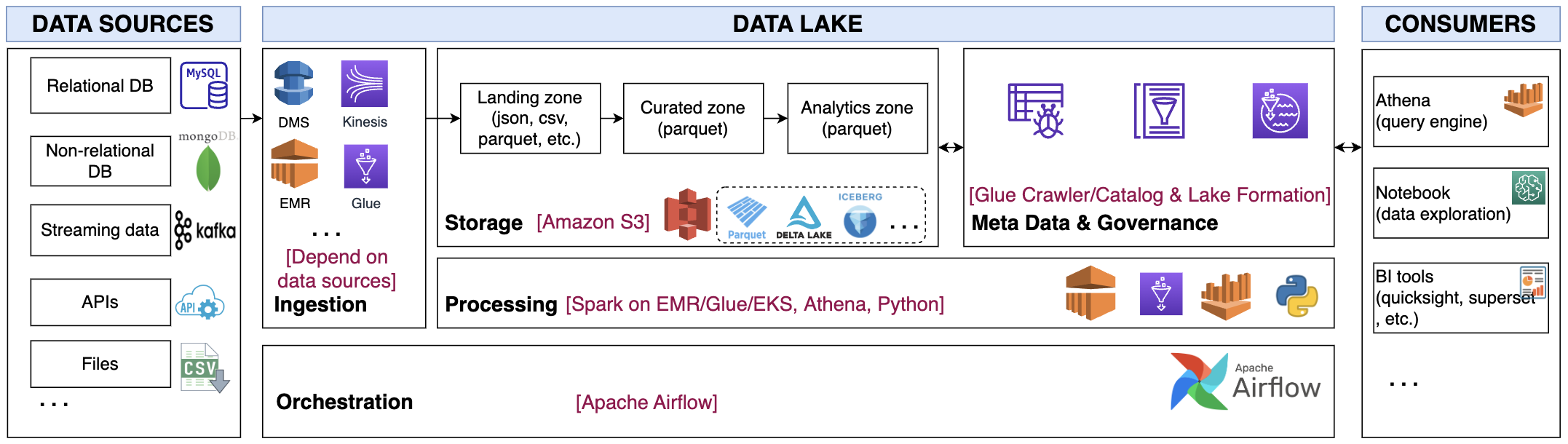
Data Platform on AWS
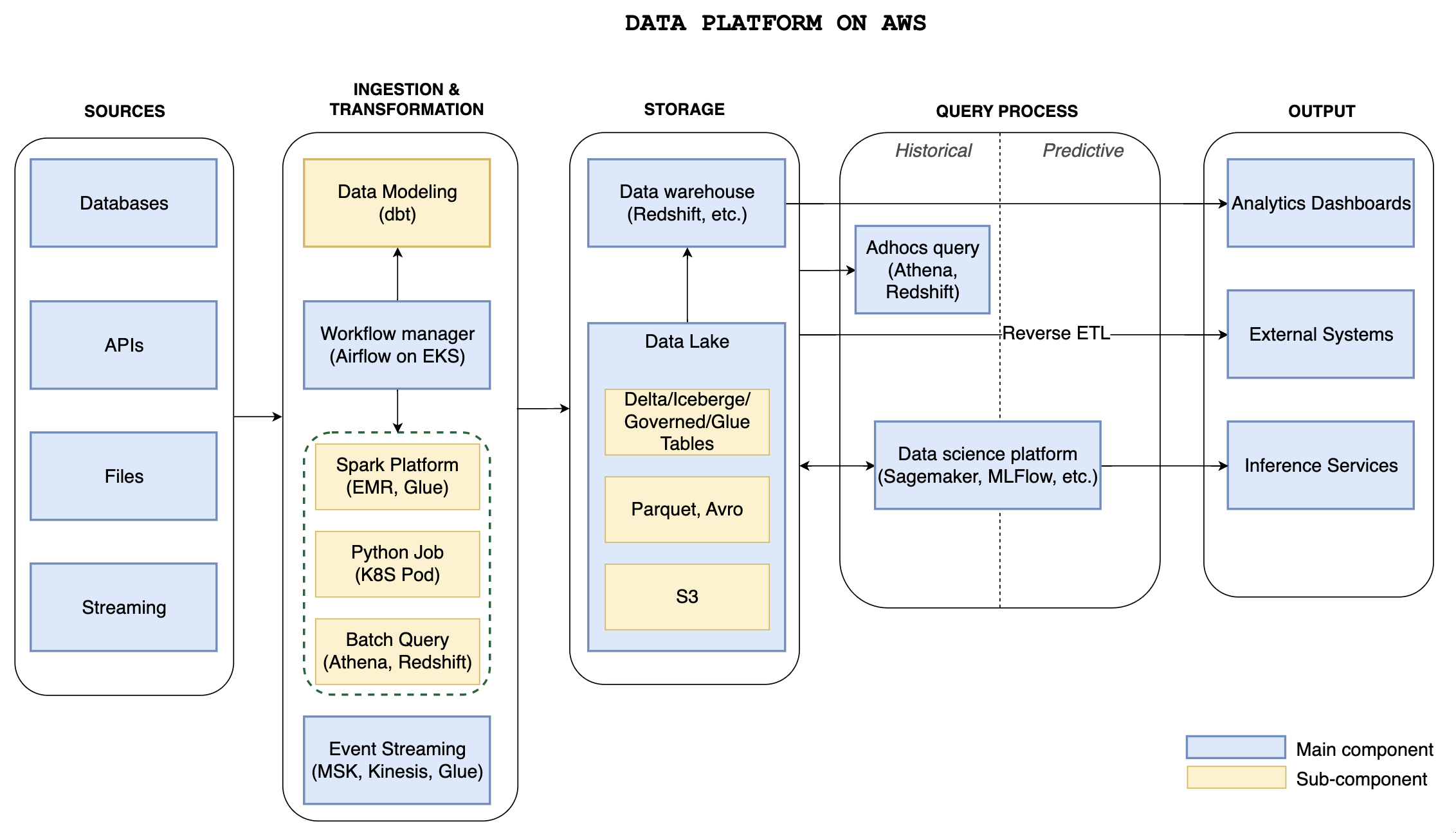
As AI continues to impact the world, the importance of data in business decision making has become increasingly apparent. Data also offers the potential to deliver greater value with less effort. To fully realize these benefits, it is essential to prioritize the development of a robust data platform architecture.
This series begins with the goal of constructing a comprehensive data platform on AWS, designed to meet the diverse needs of companies from startups to enterprises. Our objective is to create a platform that is scalable, reliable, secure, flexible, and cost-effective.
Churn rate prediction on Sparkify service

Spakify is a music streaming sevice as similar to Spotify. Every users’ activities on Sparkify application are logged and sent to Kafka cluster. To improve the business, the data team will collect data to a Big Data Platform for further processing, analysing and extracting insights info for respective actions. One of the focusing topic is churn user prediction.