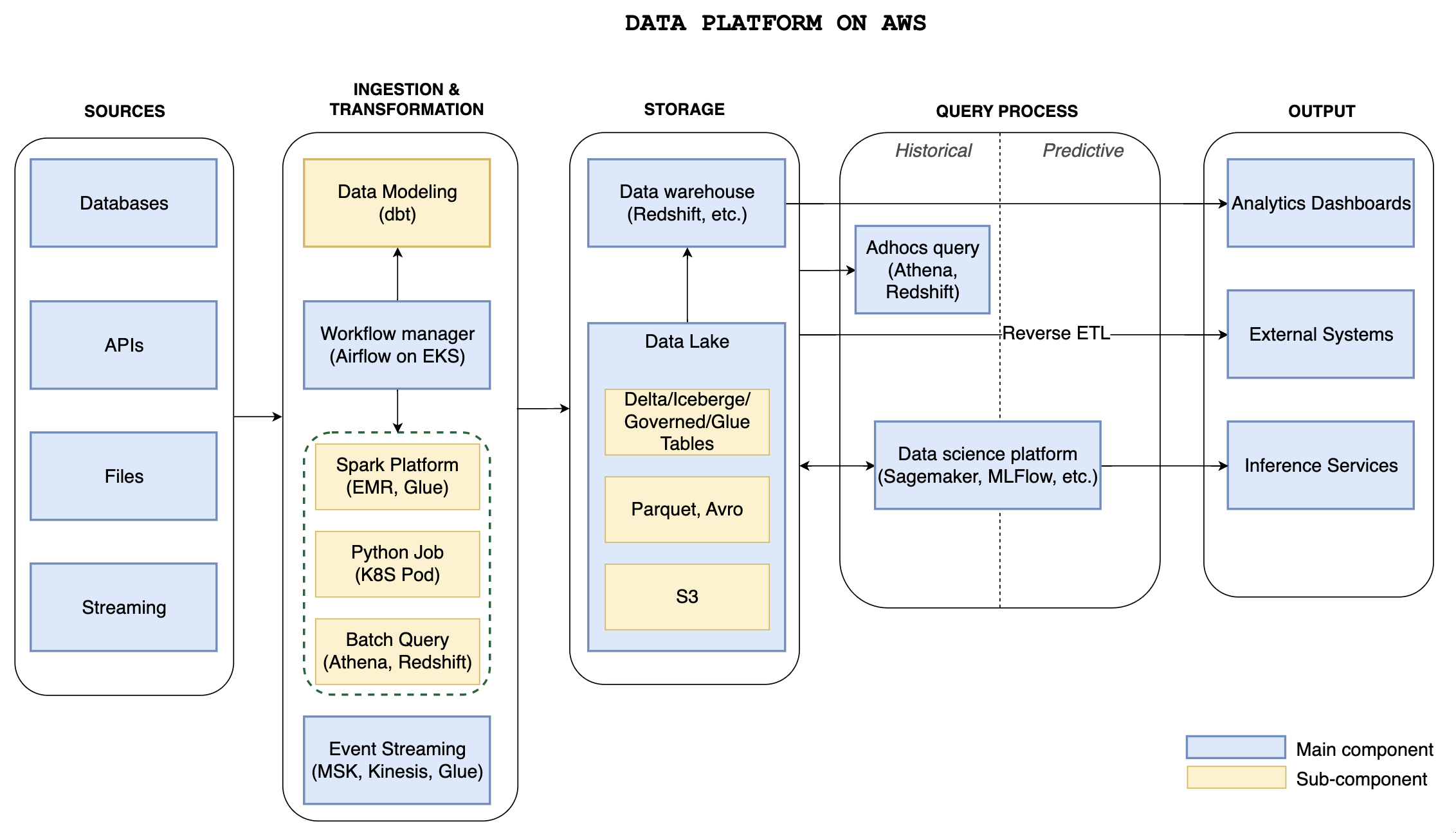
In our last post, we explored the topic of the Data Platform on AWS. This post continues the discussion by offering an in-depth look into the central component of the data platform, the data lake, which serves as the single source of truth.
A data lake is a centralized repository for storing structured and unstructured data at any scale. It helps organizations effectively store, manage, and analyze growing amounts of data. Building a data lake on AWS offers cost-effective, secure storage and real-time analysis using scalable infrastructure, robust security, and analytical tools for making data-driven decisions and improving business value.
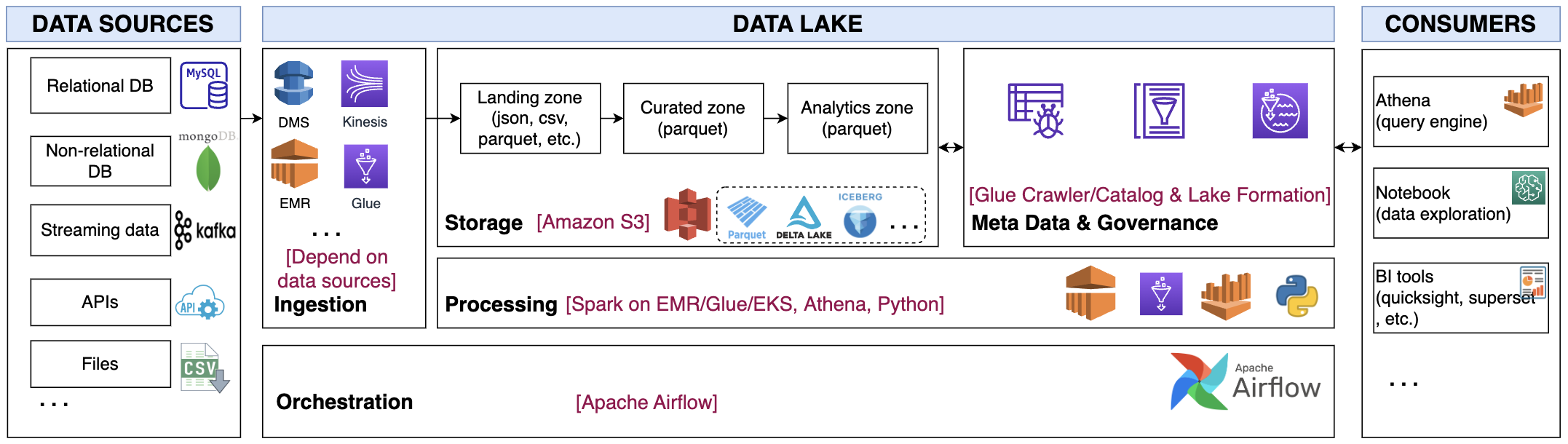
The proposed architecture is presented as below with 5 main components Ingestion, Storage, Processing, Meta Data & Governance and Orchestration.